Visual text representations
(Archiving a Twitter thread that may be deleted at some point)
I had fun working with Liz Salesky on a project that’s been cooking for a while: “Robust open-vocabulary machine translation from visual text representations”.
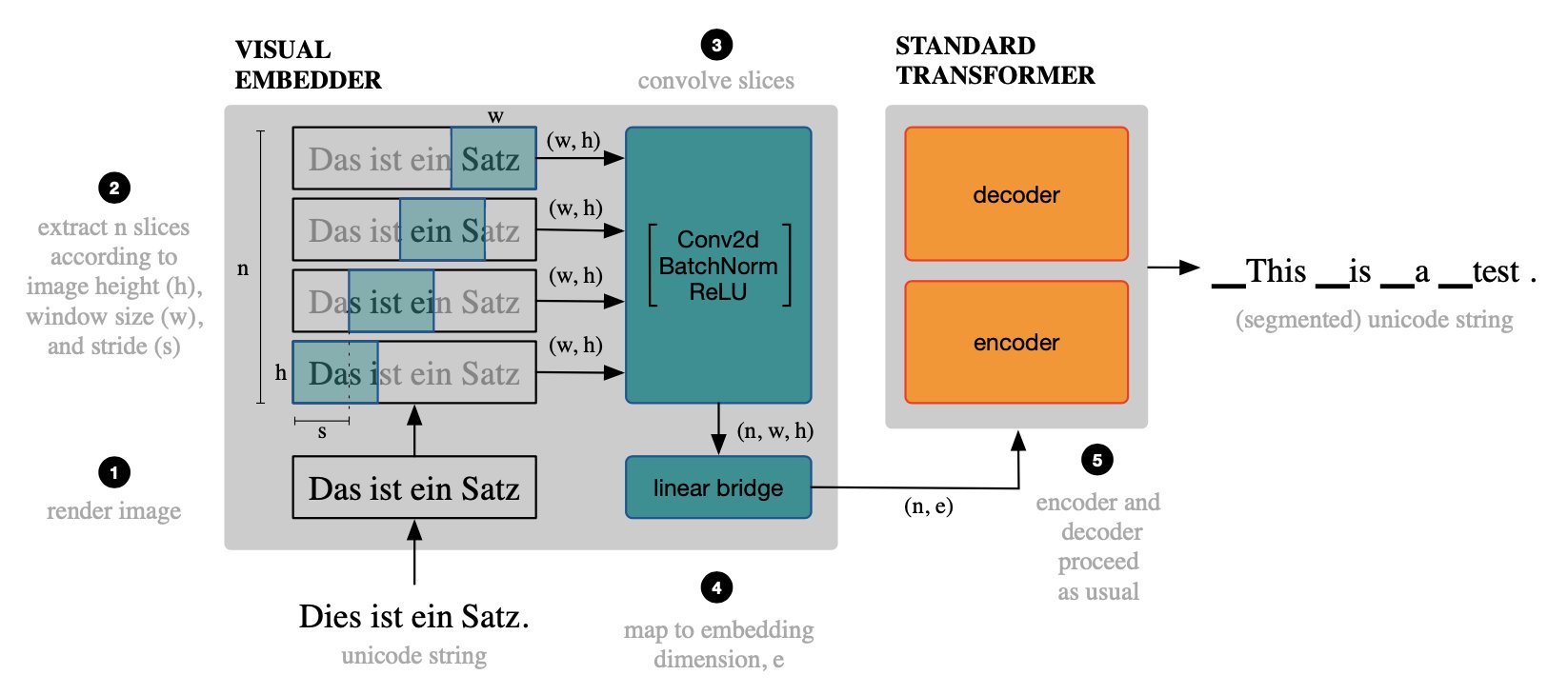
For background, it’s well-known that machine translation (and other NLP) systems are brittle when encountering noisy text, even where humans are robust (e.g., Belinkov & Bisk, 2017). Our work here stems from the observation that this “robustness gap” can be at least partially explained by the fact that humans process text visually, whereas computers use subword segmentation. Our approach is to replace the standard (subword-segmented text) embeddings with “visual text” embeddings, computed from a rendered image of the raw text that is sliced into overlapping, horizontal windows, akin to ASR.
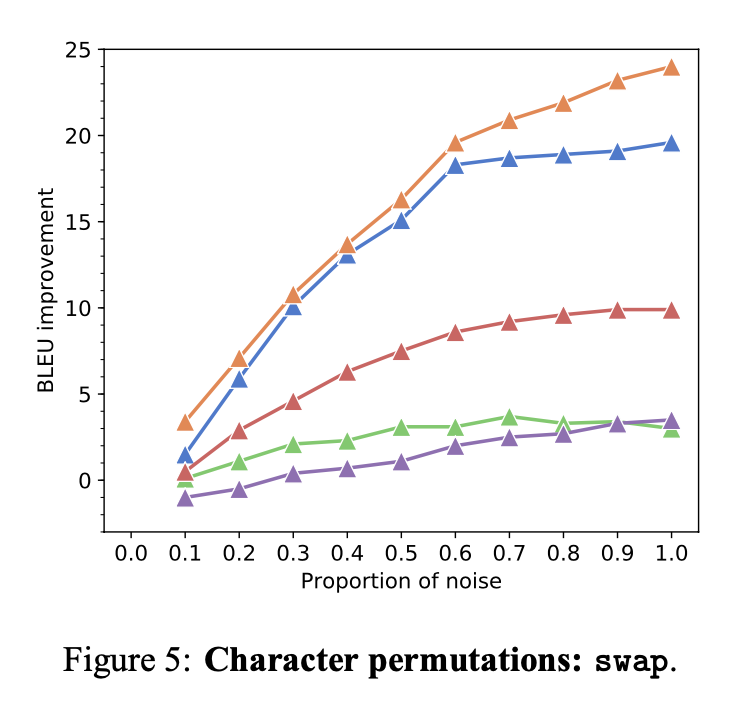
On tiny datasets (multilingual TED), we have parity with the baseline systems in Latin scripts, though we’re still lagging in other languages. (We suspect we just need more parameter search on the visual architecture). But the most remarkable result is how robust these systems are to synthetic noise. For example, swapping two random characters hoses baseline systems, but ours handle it pretty deftly.
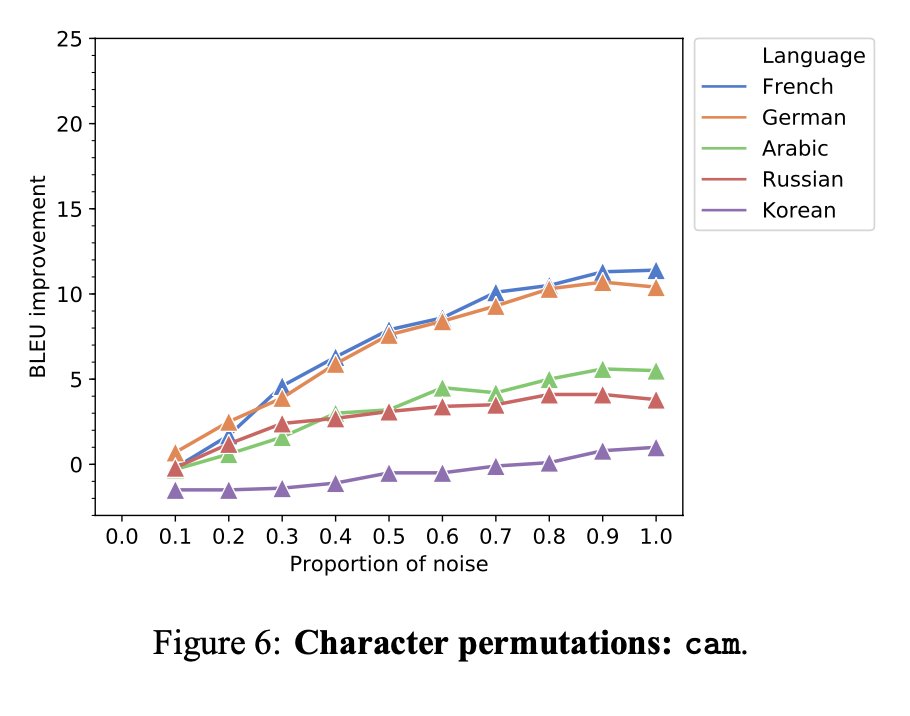
We see similar results for the so-called “Cmabrigde” spelling effect (though don’t call it that: https://www.mrc-cbu.cam.ac.uk/people/matt.davis/cmabridge/).
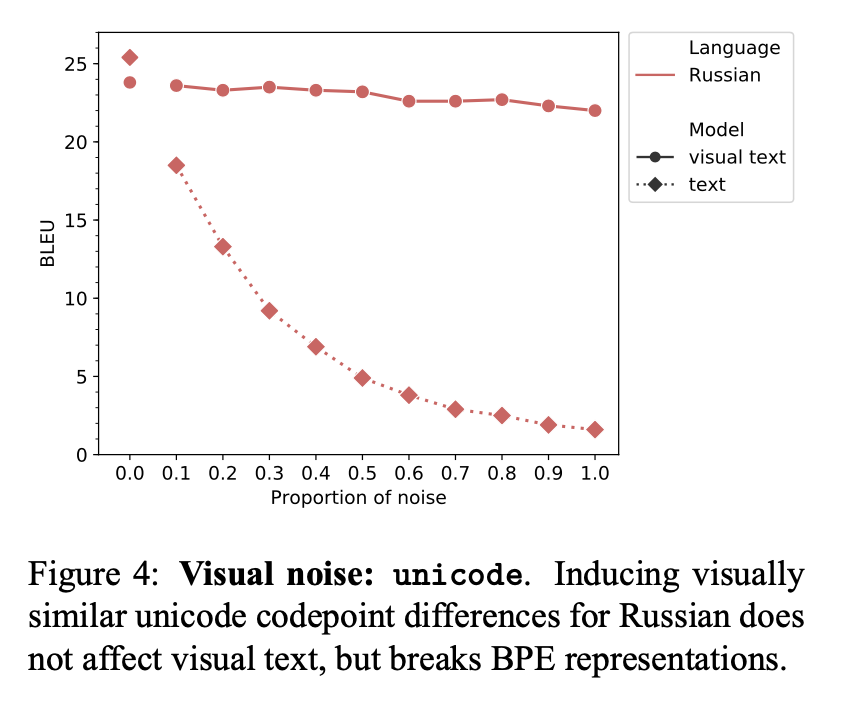
Also impressive (and obvious) is the case of spurious unicode ambiguity, as with this Russian WIPO example, where the baseline system breaks, while visual text is hardly affected.

Some of the outputs are truly impressive. We didn’t have to search hard for these.

As a side effect, we entirely eliminate the need for subword preprocessing and normalization.
Anyway, this is early work with a lot of obvious followup questions, most obviously how reasonably-sized datasets would change things. But we are excited about it, and think it has a lot of potential! (It would have been on arXiv this morning, but something appears to have gone wrong with our submission.)
Thanks to Adi Renduchintala for early (2019!) work on this project and general enthusiasm (alas, he had to finish his Ph.D.), and to Facebook Research for generously supporting it.